皮皮虾有插眼视频的功能,有时候看到需要下载的视频我先插眼然后用抓包软件在安装模拟器中浏览一遍,在浏览过程中抓包软件会分页下载视频列表(JSON文件)
然后根据视频列表用Python下载
抓包软件Fiddler4配置
查看本机局域网IP
ipconfig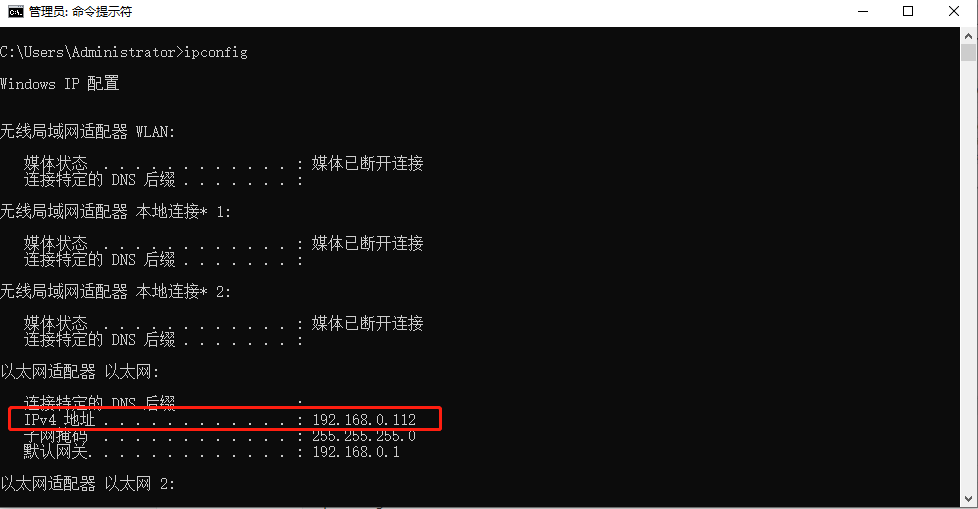
比如本机得到的是192.168.0.112
夜神模拟器配置
PS:注意模拟器运行的Android版本最好是5.1可以使用多开器,开一个5.1的版本
- 打开模拟器的设置–>找到WLAN
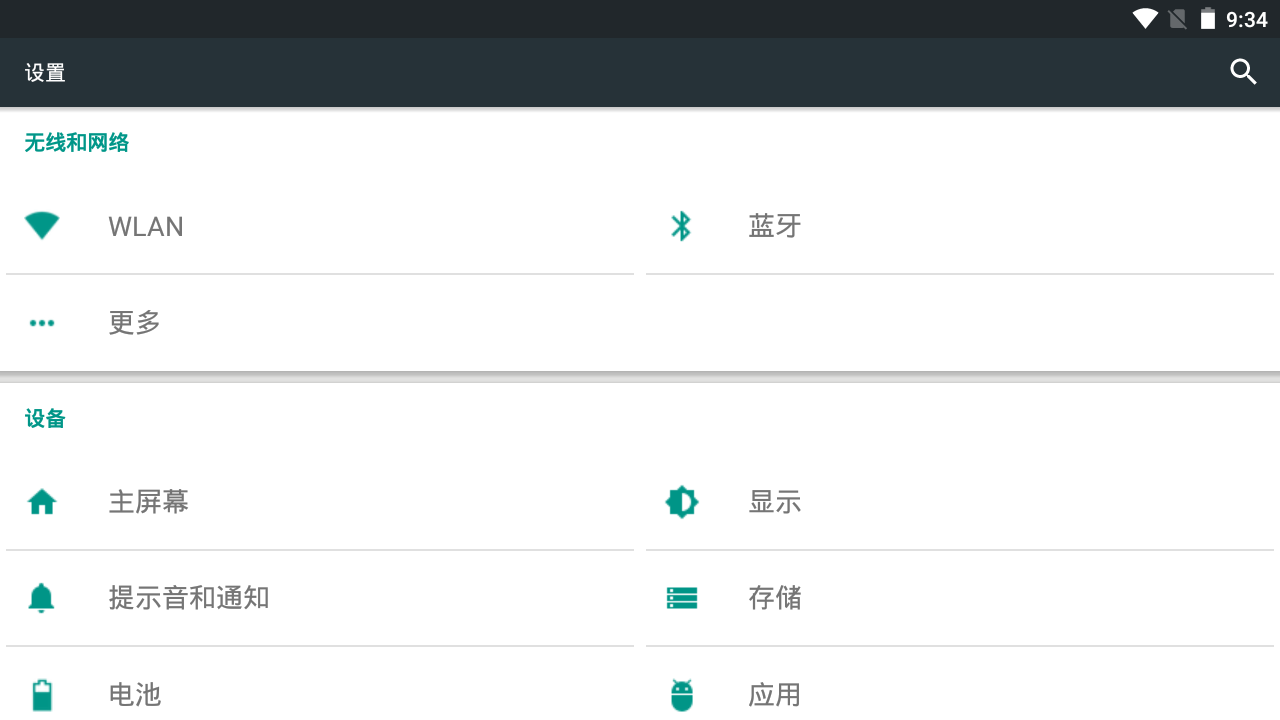
- 长按虚拟wifi–>修改网络
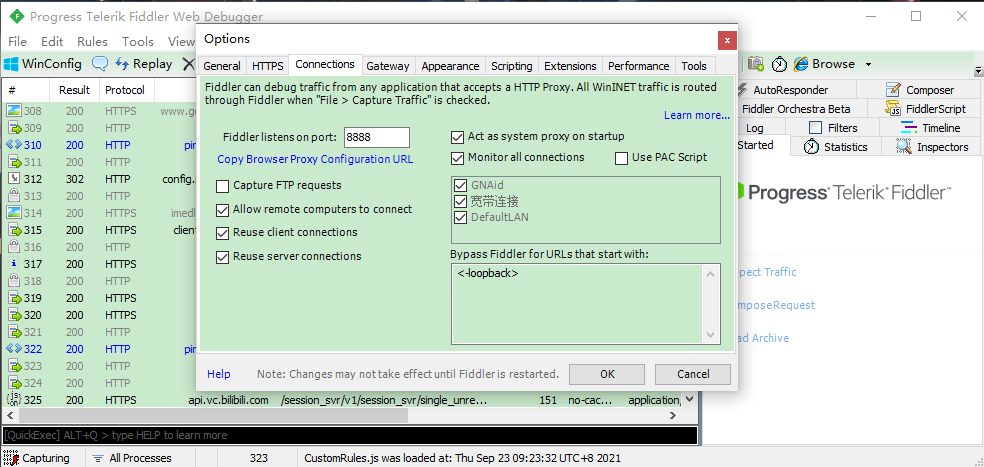
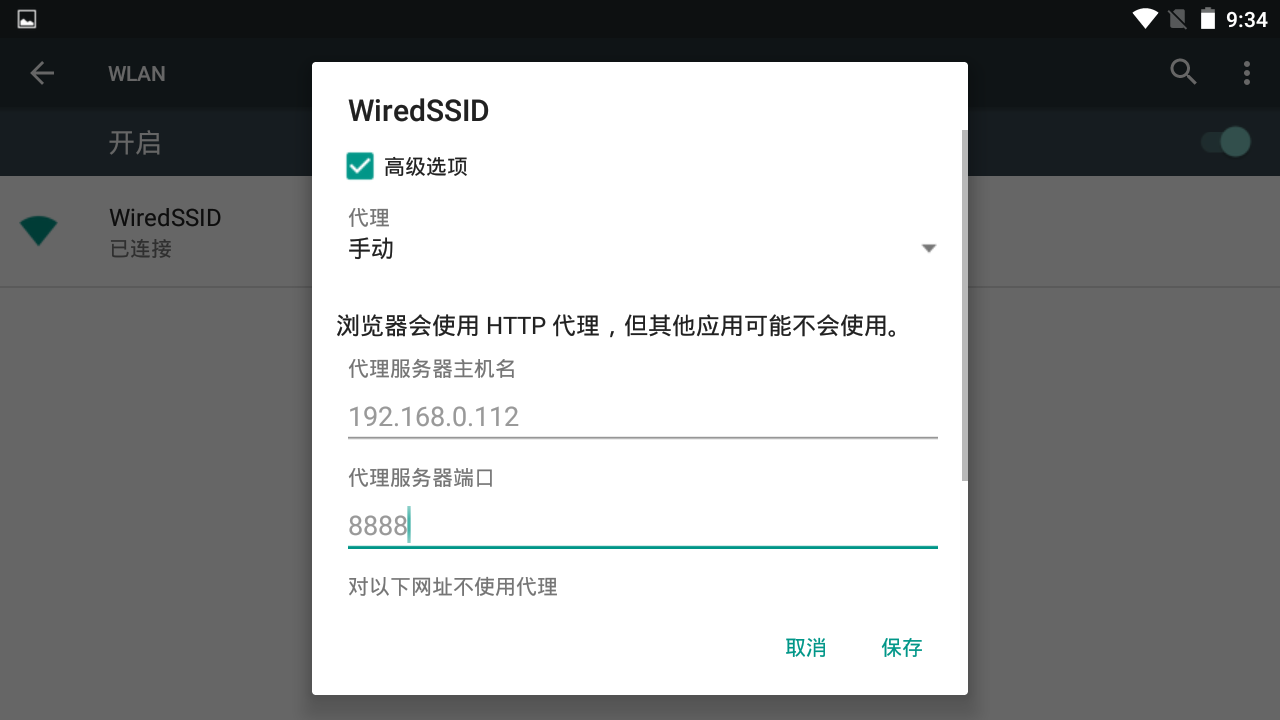
- 勾选高级选项–>将代理改为手动–>IP地址输入刚刚得到的IP–>端口输入8888
打开模拟器的默认浏览器输入网址IP:8888,比如192.168.0.112:8888
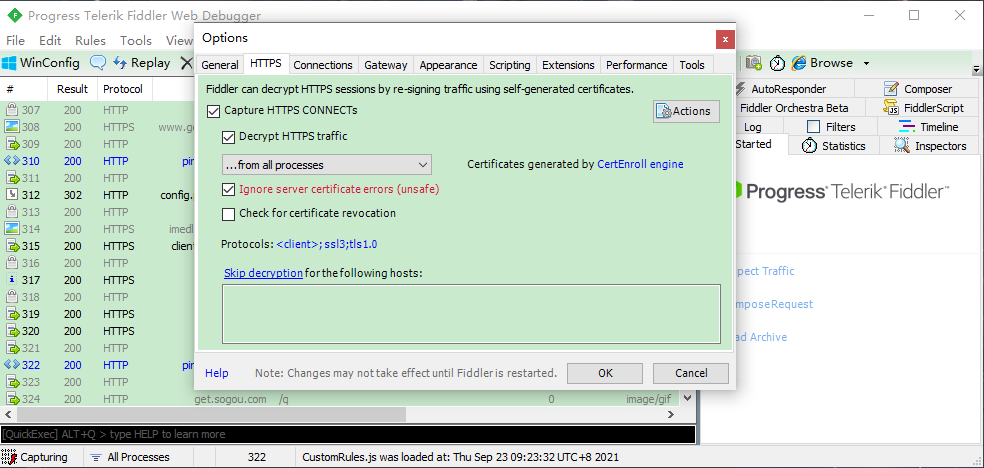
然后点FiddlerRoot certificate 下载根证书
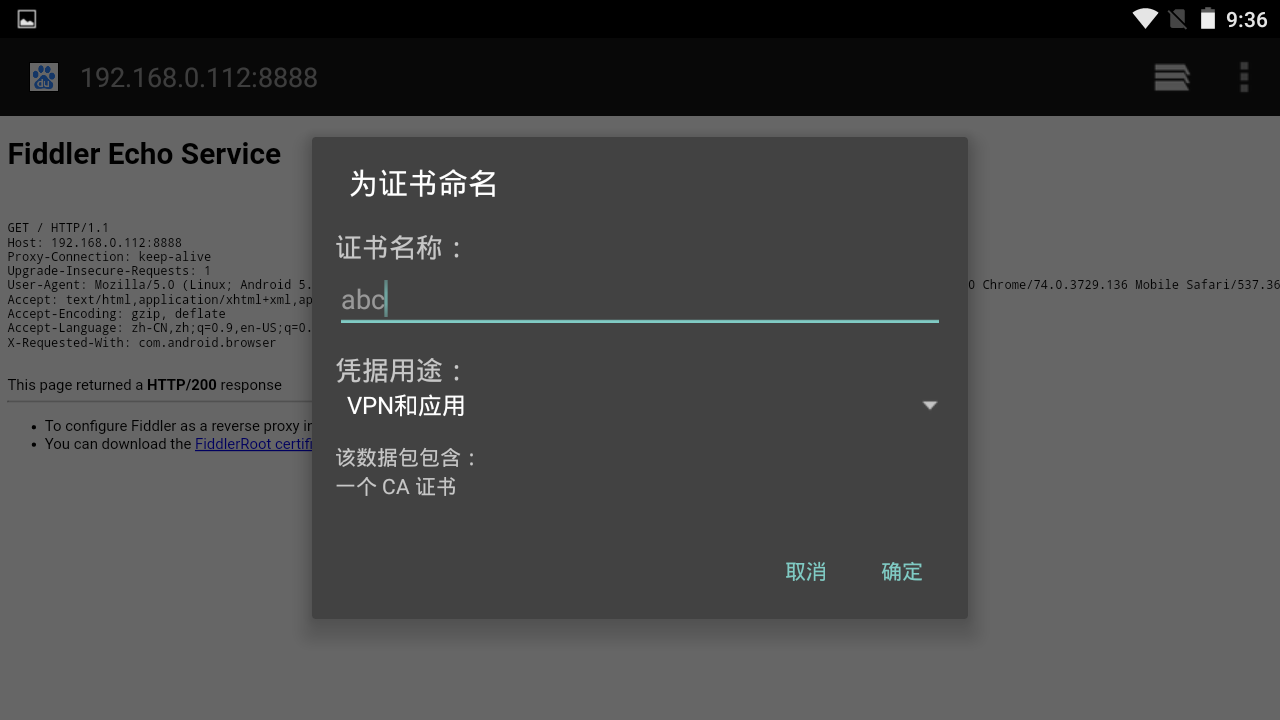
- 安装根证书随意输入名称并设置模拟器的密码
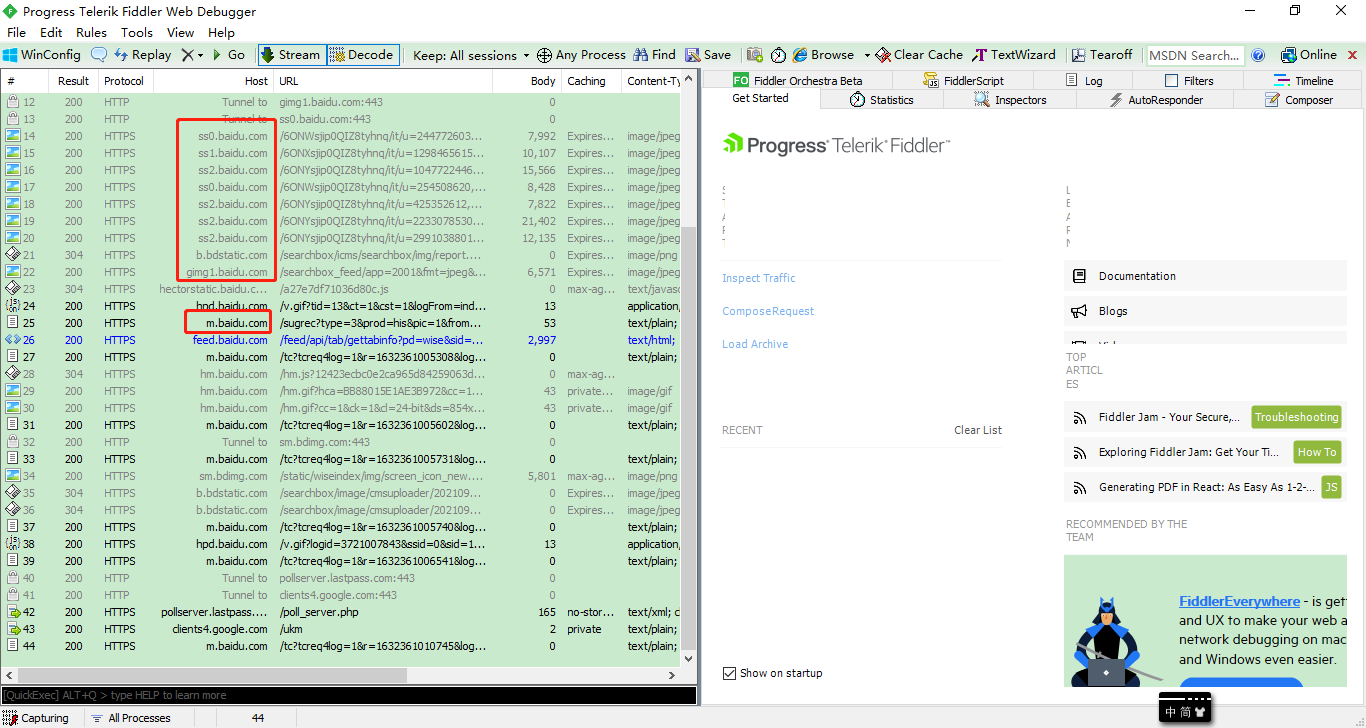
皮皮虾APP浏览插眼内容
- 下载皮皮虾APP
- 登陆皮皮虾
- 向下滑动插眼内容
使用URL排序
/bds/ward/list?layout_style=…….
这样的JSON文件都是下载的临时视频列表
选中这些文件然后右击保存到文件夹
jsonfiles 与 Python文件在同一个目录下
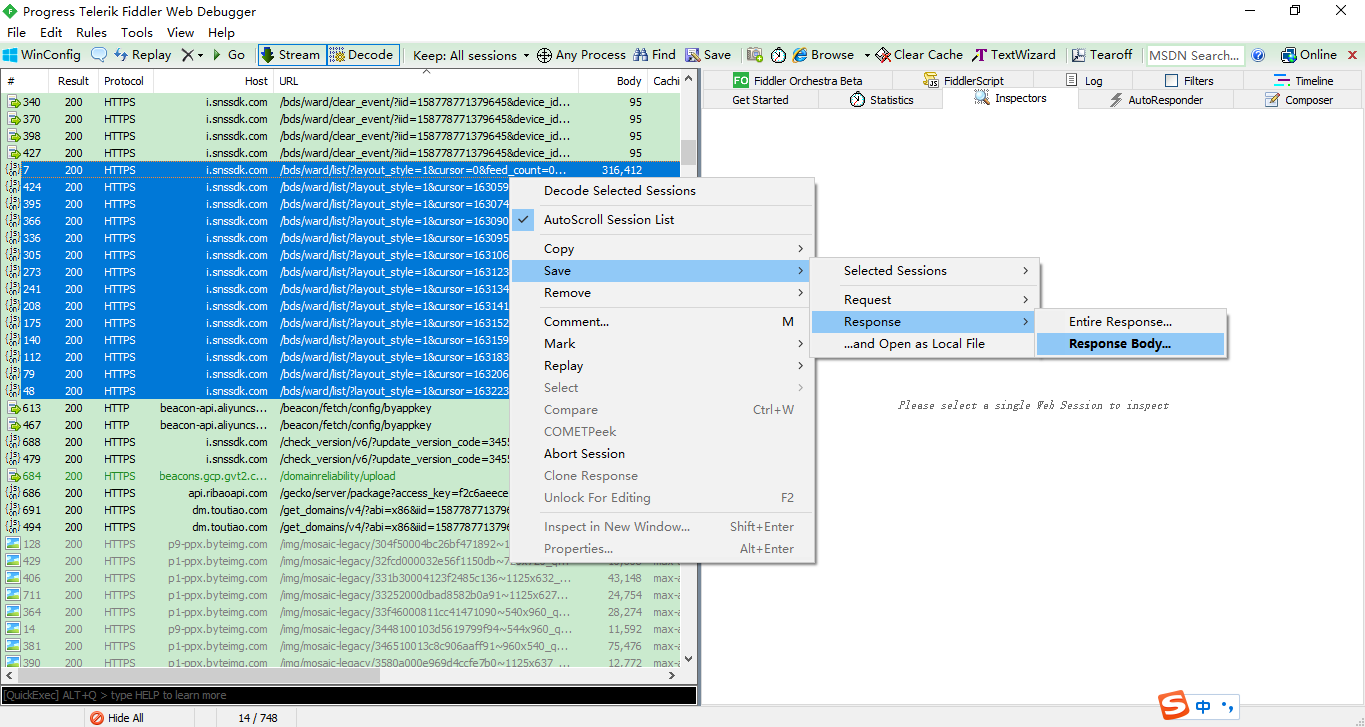
然后运行 ppxeye.py 程序 自动下载
Python源码
'''
下载插眼视频
https://i.snssdk.com/bds/ward/list/?layout_style=1&cursor=1586475848202&feed_count=17&list_type=userwards&user_id=61617304127&direction=2&iid=158778771379645&device_id=1952320808301352&ac=wifi&channel=tengxun&aid=1319&app_name=super&version_code=345&version_name=3.4.5&device_platform=android&ssmix=a&device_type=SM-G973N&device_brand=samsung&language=zh&os_api=22&os_version=5.1.1&uuid=351564155372295&openudid=c41d1926c38f3dca&manifest_version_code=345&resolution=720*1280&dpi=240&update_version_code=34550&_rticket=1621843950952&cdid=9713b490-0abc-4638-bbe6-c1c8a6d04e28&app_region=CN&last_channel&sys_region=CN&time_zone=Asia%2FShanghai&app_language=ZH&carrier_region=CN&last_update_version_code=0&ts=1621843950
'''
import requests,json,os
from jsonpath import jsonpath
def ppxvideodownload(foldername,videoid,name,content,dlurl):
"""
皮皮虾视频下载
:param foldername: 目录
:param videoid: 视频ID
:param name: 作者
:param content: 标题
:param dlurl: 下载地址
:return:
"""
filename=name+"_"+videoid+"_"+content
print(filename)
req=requests.get(dlurl)
# 打印标题
try:
f = open(foldername + "\\" + filename + '.mp4', 'wb')
f.write(req.content)
f.close()
except:
print("标题有特殊字符")
filename = name + "_" + videoid
print(filename)
f = open(foldername + "\\" + filename + '.mp4', 'wb')
f.write(req.content)
f.close()
def deljson(item_ancestor_id,item_name,item_content,item_type,item_videourl):
'''
格式化json将不是视频类型的删除元素
:param item_ancestor_id:
:param item_name:
:param item_content:
:param item_type:
:param item_videourl:
:return:
'''
i=0
while i<len(item_type):
if item_type[i]==1:
print('第{'+str(i)+'}个要删除')
item_name.pop(i)
item_ancestor_id.pop(i)
item_type.pop(i)
item_content.pop(i)
i=i+1
if None in item_ancestor_id:
deljson(item_ancestor_id,item_name,item_content,item_type,item_videourl)
else:
pathname = 'eye'
if not os.path.exists(pathname):
os.makedirs(pathname)
x = 0
for videoid in item_ancestor_id:
ppxvideodownload(pathname, item_ancestor_id[x],item_name[x], item_content[x], item_videourl[x * 2])
x = x + 1
def decojsonfile(jsonfilename):
'''
解析JSON文件并且将下载参数传给ppxvideodown
:param jsonfilename: json文件名称
:return:
'''
print(jsonfilename)
with open(jsonfilename, 'r',encoding='utf-8') as f:
filedata = json.load(f)
#获得作者
item_name=jsonpath(filedata,"$.data.data.*.item.author.name")
#获得视频ID
item_ancestor_id=jsonpath(filedata,"$.data.data.*.item.ancestor_id")
#获得视频ID
item_type=jsonpath(filedata,"$.data.data.*.item.item_type")
#获得视频标题
item_content=jsonpath(filedata,"$.data.data.*.item.content")
#获得视频下载地址
item_videourl=jsonpath(filedata,"$.data.data.*.item.origin_video_download.url_list.*.url")
deljson(item_ancestor_id,item_name,item_content,item_type,item_videourl)
if __name__ == '__main__':
jsonfiles=os.listdir('jsonfiles')
for jsonfile in jsonfiles:
decojsonfile('jsonfiles\\'+jsonfile)运行效果
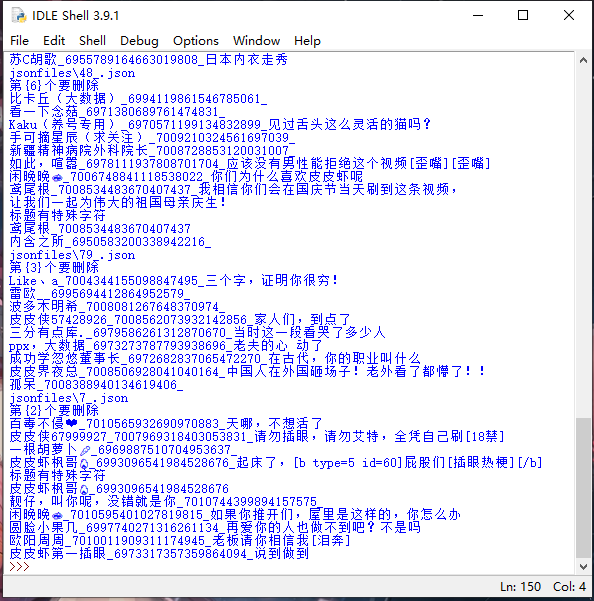
在同样的目录 eye 目录下就是下载的视频了
视频的命名规则是
作者_视频ID_标题



