需求分析
平常在家看看电影,电视剧,最近剧荒了,在B站看到木鱼水心的一些视频电影解说,他推荐了一些电影和电视剧
但是他发布的视频太多了 有999个视频以上,一个个去看太累了,重复的事情就交给电脑吧!
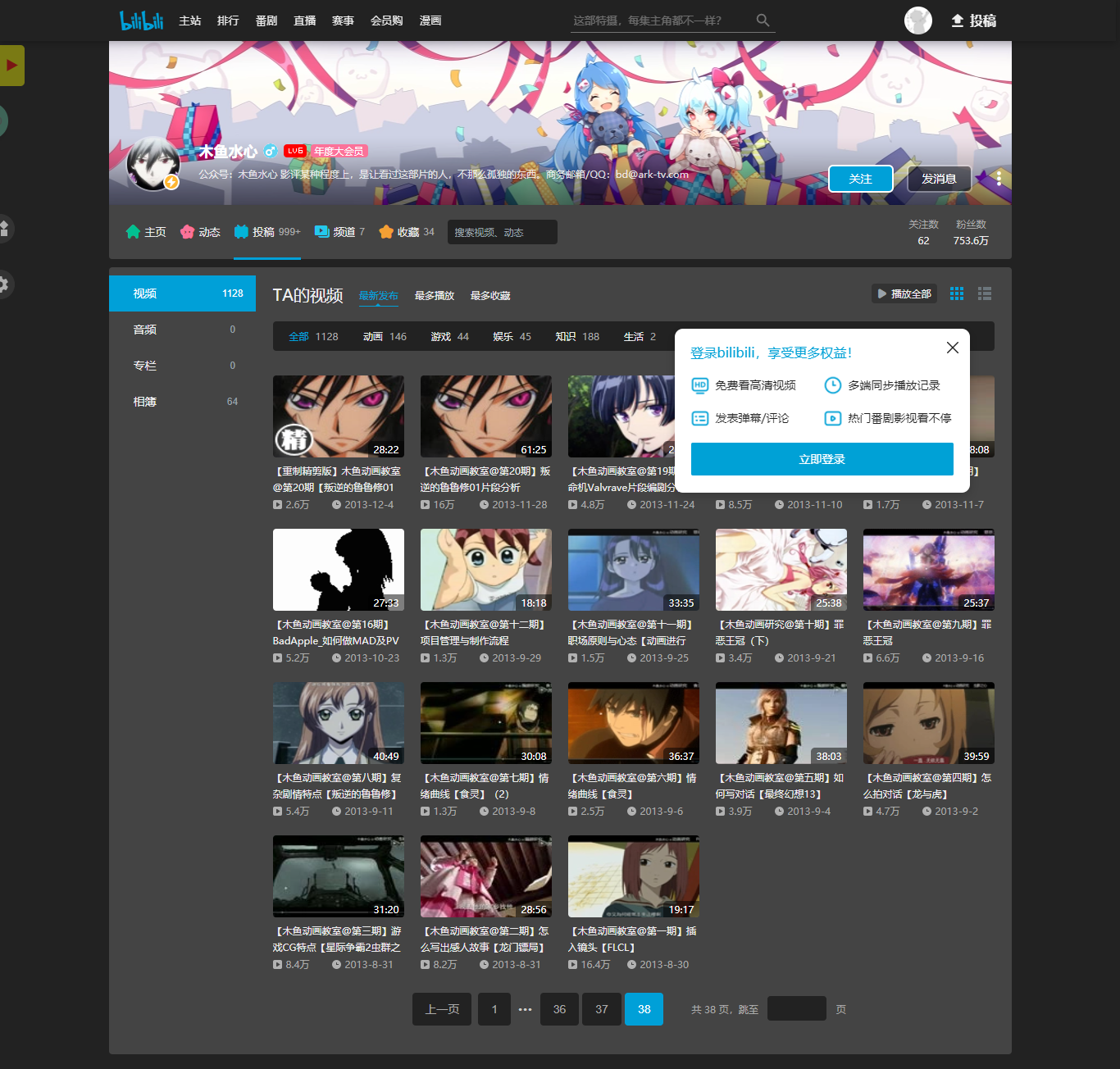
有的一部分我看过了比如《肖生克的救赎》《阿甘正传》等等,他推荐的视频很多,我怎么得到这些视频列表呢?
人生苦短,我用Python
Python实现
URL=皮皮虾视频的分享链接然后做个拼接就可以使用了
需要用到的包有
- re(自带)
- json(自带)
- requests(初次安装 pip install requests)
- jsonpath(初次安装 pip install jsonpath)
由于不是全部视频都是电影解说 视频标题中带有“木鱼微剧场”关键字的是我需要
将视频标题取得 然后 做个判断 符合条件就保存到文本文件中
源码
import re,requests,json
from jsonpath import jsonpath
def envideolisttitles(url):
'''
解析B站指定UP主的视频列表标题
:param url:视频列表
:return:
'''
headers = {'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.5',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'}
req = requests.get(url=url, headers=headers)
filedata=json.loads(req.text)
item_name=jsonpath(filedata,"$.data.list.vlist.*.title")
for it in item_name:
if it.find("木鱼微剧场")!=-1:
with open('muyushuixin.txt','a+') as f:
f.writelines(it+'\n')
if __name__ == '__main__':
for n in range(38):
url='https://api.bilibili.com/x/space/arc/search?mid=927587&ps=30&tid=0&pn='+str(n+1)+'&keyword=&order=pubdate&jsonp=jsonp'
print(url)
envideolisttitles(url)```


