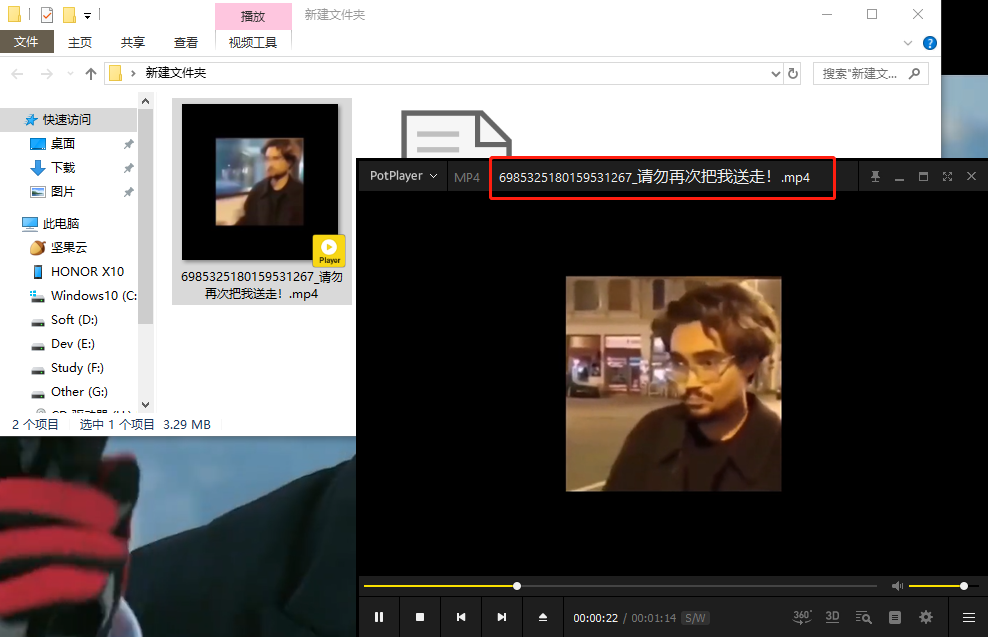
需求分析
皮皮虾无水印下载视频,偶然间发现这个网站
http://tenapi.cn/ppx/请求示例
https://tenapi.cn/ppx/?url=https://h5.pipix.com/s/hukXsy/返回数据
{
"code": 200,
"title": "标题交给你们了。",
"cover": "https://p1-ppx.byteimg.com/img/mosaic-legacy/2ab8400068ec7576befea~272x480_q80.jpeg",
"url": "http://v3-ppx.ixigua.com/5ed98deb58c533527e24ec0220a28992/5f62eec8/video/tos/hxsy/tos-hxsy-ve-0076/41064fc495f04f029e8629421b1352fd/?a=1319&br=1041&bt=347&cr=0&cs=0&dr=3&ds=1&er=&l=2020091712060301001404314826001048&lr=&mime_type=video_mp4&qs=0&rc=anl4PGd0bDl4bjMzZGYzM0ApZGk1NTRpNjs5N2k4NDxnZGctYGsucWdjNDVfLS0yMS9zczMxLV82XjA0NDA0XzMuY2I6Yw%3D%3D&vl=&vr="
}Python实现
URL=皮皮虾视频的分享链接然后做个拼接就可以使用了
需要用到的包有
- re(自带)
- json(自带)
- requests(初次安装 pip install requests)
为了避免重复下载 我将每个皮皮虾的原始ID和标题作为视频的文件名
源码
import re,requests,json
'''
皮皮虾无水印下载--解析版本
2020-10-06
'''
def ppxdownloadmp4(ppx_url):
#ppx_url='https://h5.pipix.com/s/JyeSQ73/'
response = requests.get(ppx_url)
# 得到跳转真实URL
jempurl = response.url
# 得到视频ID
id = re.findall('https://h5.pipix.com/item/(.*?)\?app_id', jempurl)
#解析网址
req=requests.get('https://tenapi.cn/ppx/?url='+ppx_url)
html=req.text
# print(req)
# print(html)
#解析JSON
jg=json.loads(html)
if len(id)>0:
print(id[0])
else:
print("无法获得视频ID")
try:
print(jg['title'])
except:
print("无法打印标题")
print(jg['url'])
response=requests.get(jg['url'])
f=open(id[0]+'_'+jg['title']+'.mp4','wb')
f.write(response.content)
f.close()
if __name__ == '__main__':
while True:
try:
ppx_url = input('输入分享网址:')
ppxdownloadmp4(ppx_url)
except KeyError:
pass
使用方法
皮皮虾版本:
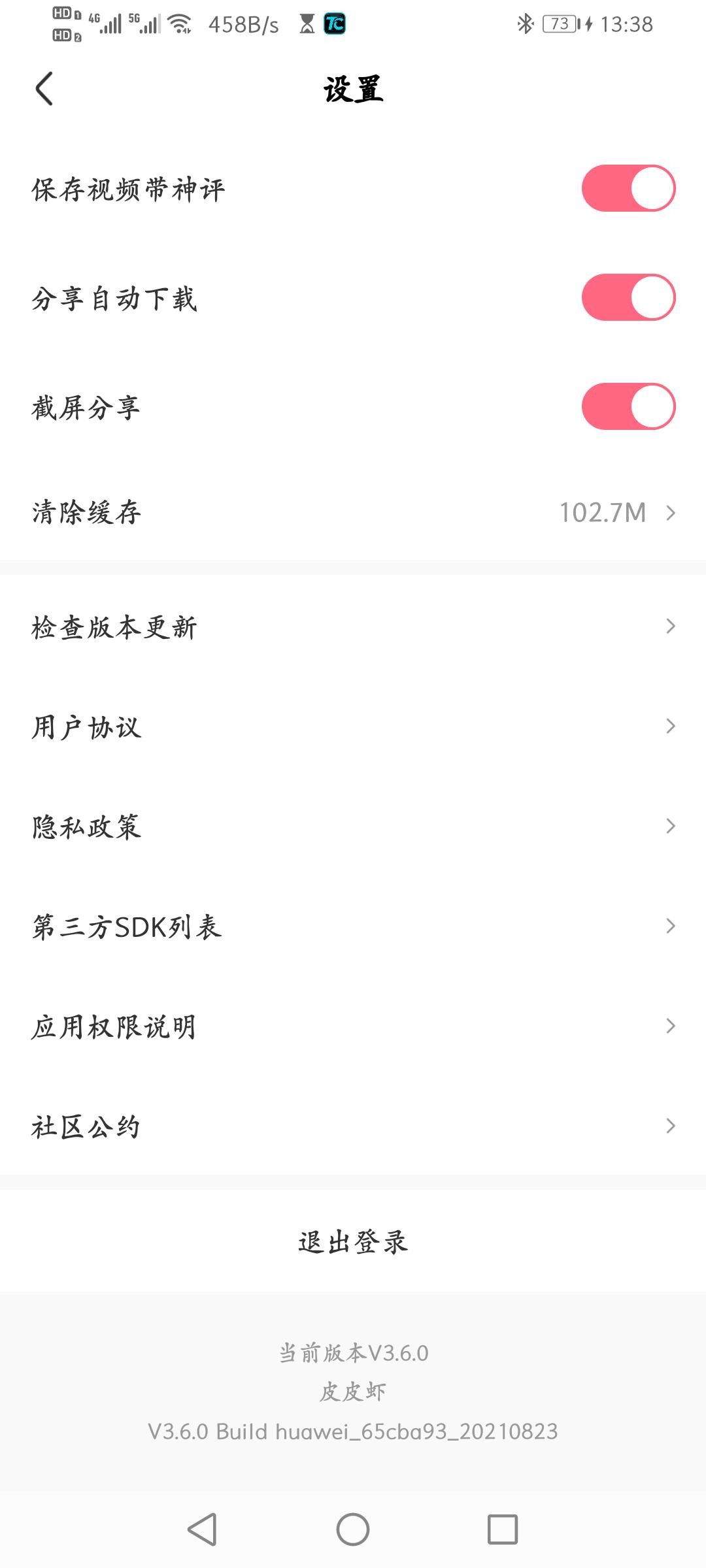
- 找到需要下载的视频点 分享 按钮
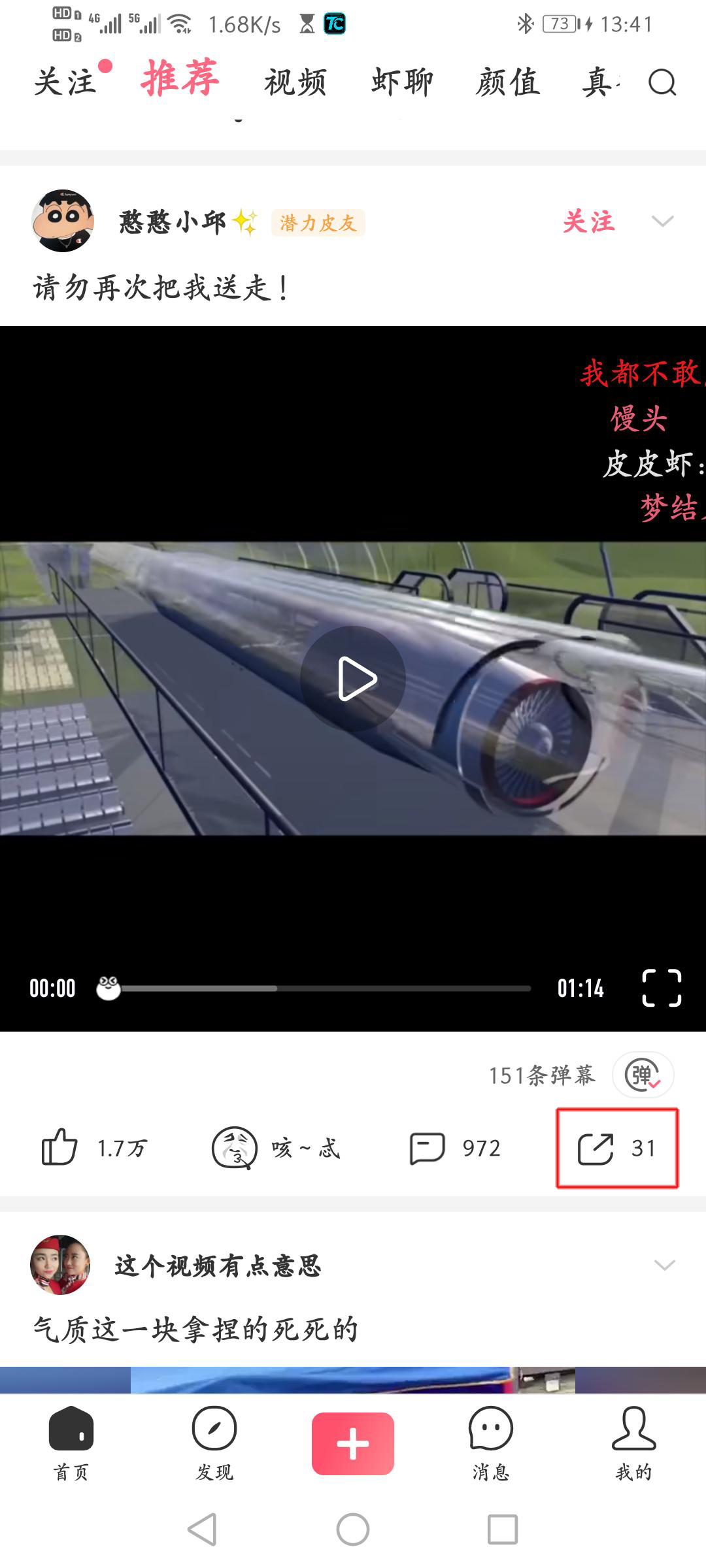
- 选择 复制链接
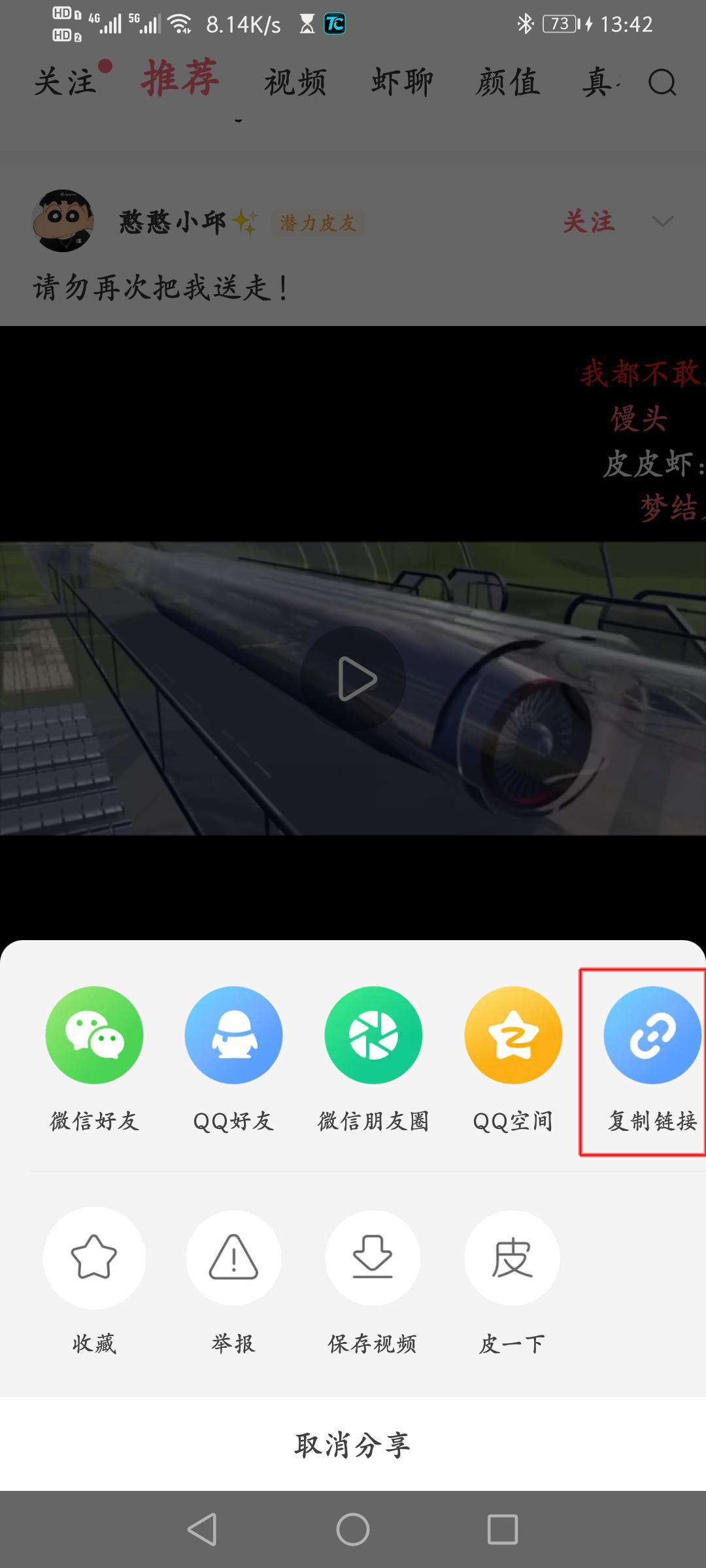
- 在运行的ppx.py 中粘贴刚刚的地址 回车 将打印该视频的ID 和 标题 如果标题有特殊表情则打印失败
- 最终效果